Catalogue des subbox — intelligence (LLM & RAG)
◆ Ingénieur IA ● Profil digitalLes subbox d’intelligence mobilisent les moteurs LLM et le RAG. Elles ne chargent généralement pas leurs données au chargement du dashboard : elles attendent une question utilisateur.
Réponses et conversations LLM
llmresponse
Réponse générée par un LLM à partir des données de la requête et d’un promptTemplate (placeholders {{variable}} ou {{FILTER_id}}). Rendu par app-chart-llm.

Rendu du type llmresponse.
Paramètres subboxOptions principaux :
Option |
Effet |
|---|---|
promptTemplate |
Gabarit du prompt avec placeholders {{variable}}. |
systemPrompt |
Instructions système du modèle. |
model |
Modèle LLM (gpt-4o-mini, gpt-4o, …). |
splitData |
Découpe les données en lots pour les gros volumes. |
subboxOptions:
promptTemplate: "Résume ce texte : {{summary}}"
model: gpt-4o-mini
chatbot
Assistant lié à un corpus : RAG systématique si des embeddings sont disponibles. Attend une question utilisateur. À distinguer de assistant (sans RAG automatique).
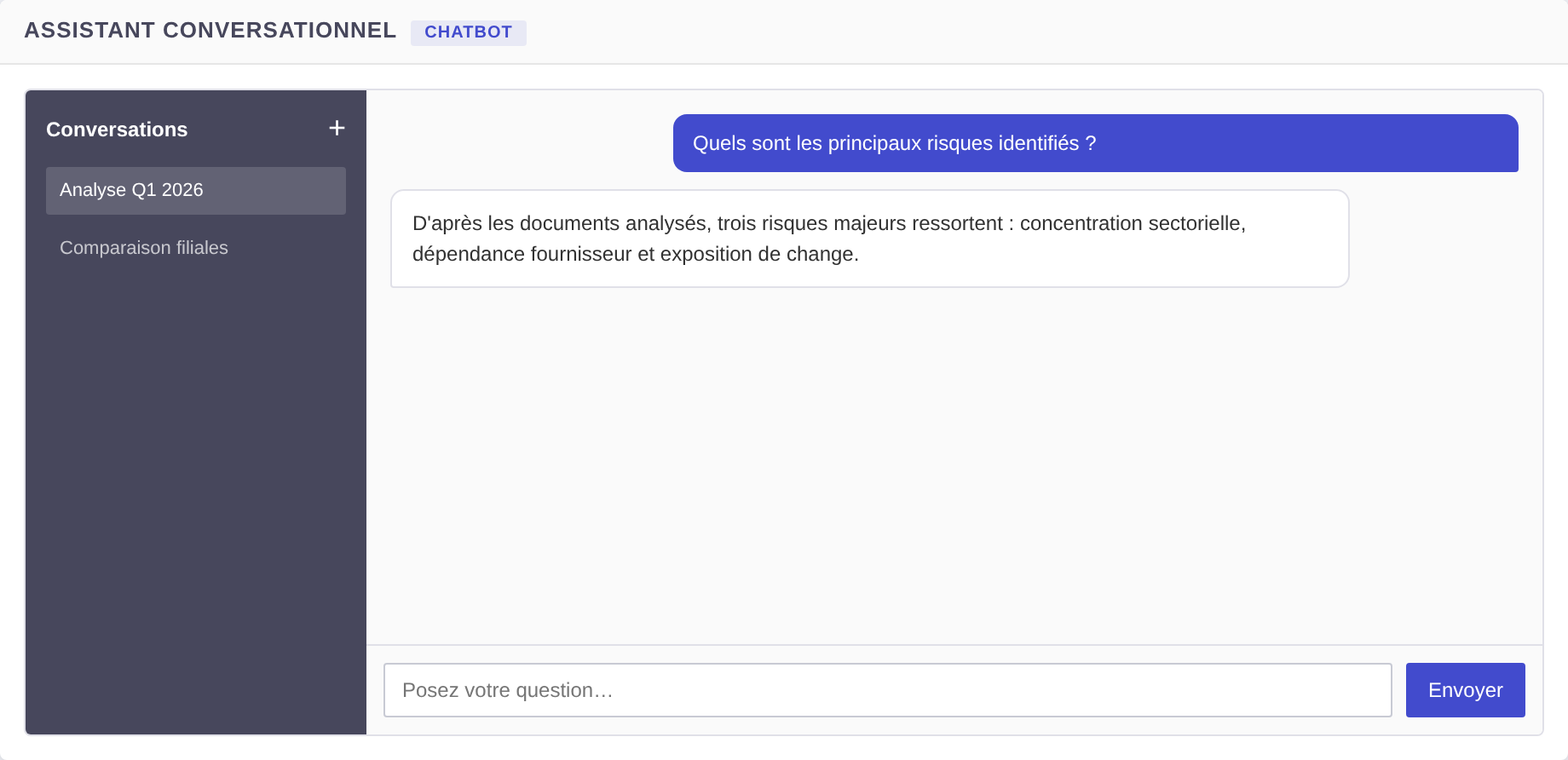
Rendu du type chatbot.
Paramètres subboxOptions principaux :
Option |
Effet |
|---|---|
enableChatbot |
Si false, le composant ne s’affiche pas (défaut true). |
promptTemplate / systemPrompt |
Template de prompt et instructions système. |
embedding / col_text / col_vector |
Active et configure le retrieval vectoriel. |
preparedPrompts |
Questions prédéfinies. |
model |
Modèle LLM. |
userInstruction |
Instructions système complémentaires. |
assistant
Assistant privé multi-provider, sans RAG automatique. Souveraineté des clés gérée par l’organisation, catalogue de providers, et Playbooks (skills métier) forkables. Persiste dans les mêmes tables que le chatbot.
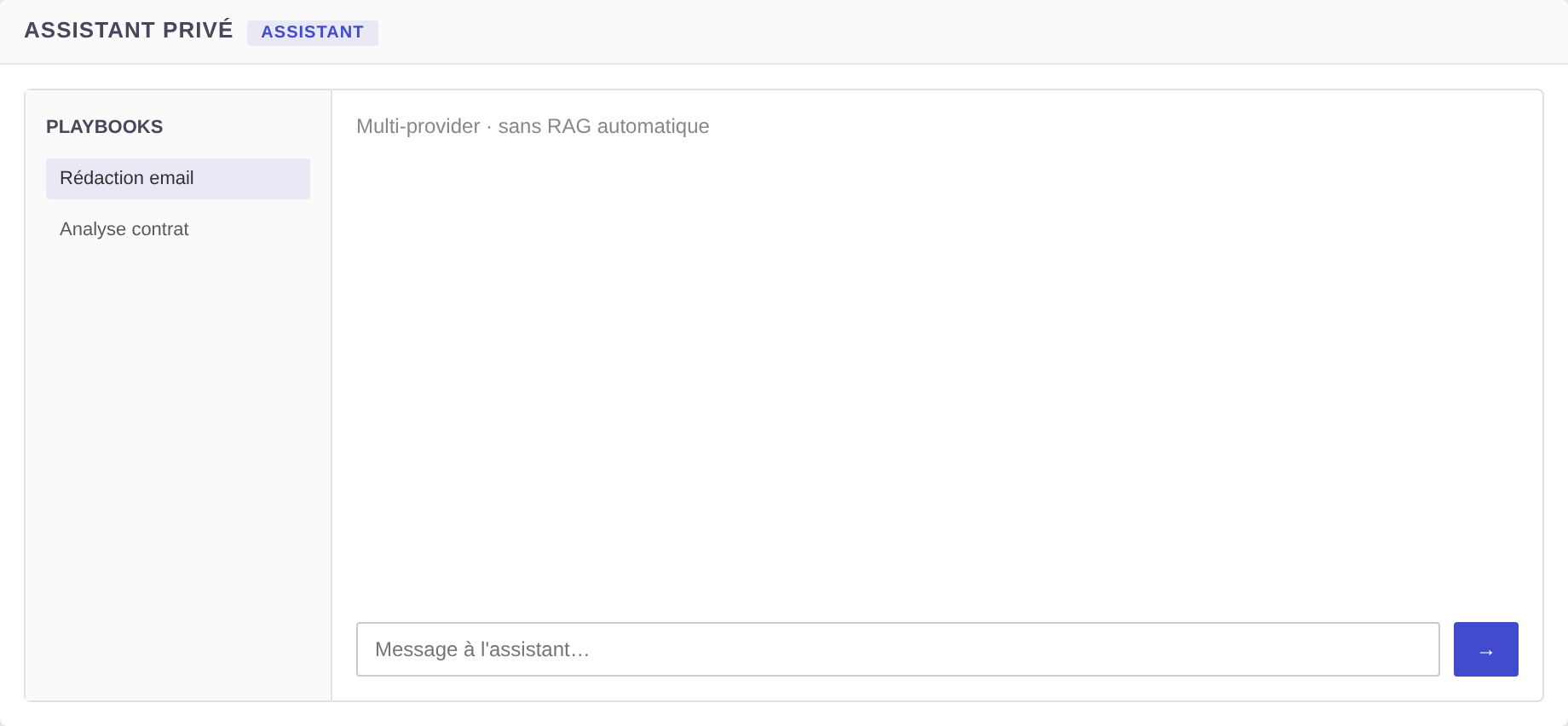
Rendu du type assistant.
Paramètres subboxOptions principaux :
Option |
Effet |
|---|---|
providers |
Catalogue de providers LLM disponibles. |
playbooks |
Skills métier (system_prompt + function_tag). |
rag
Question-réponse sur des documents : l’API récupère les sections pertinentes (filtres + similarité vectorielle optionnelle), puis le LLM répond. Endpoint : POST /llm/rag.
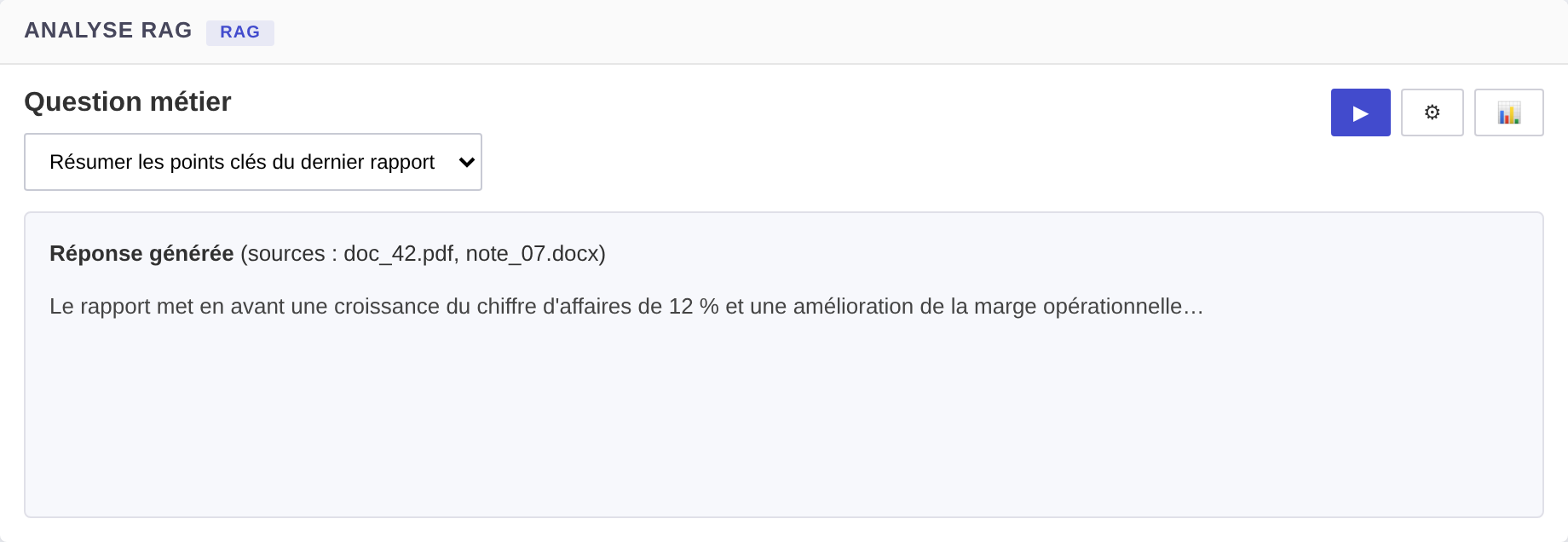
Rendu du type rag.
Paramètres subboxOptions principaux :
Option |
Effet |
|---|---|
ragQuery |
Requête SQL de récupération des documents (sinon subboxQuery). |
col_text / col_vector |
Colonnes texte et vecteur. |
comparator |
Opérateur pgvector : <-> (distance) ou <=>. |
embedding |
Active le tri par similarité au vecteur de la question. |
limit / docs_limit |
Nombre maximal de documents renvoyés. |
promptTemplate / systemPrompt |
Prompt ({{query}}) et instructions. |
preparedPrompts |
Questions prédéfinies. |
filterFrom / filterField |
Filtre dashboard injecté dans ragQuery. |
use_raw |
True pour les requêtes complexes (WITH, UNION ALL). |
ragPersist / ragPersistRecordId |
Enregistre les réponses dans une conversation. |
subboxOptions:
ragQuery: >
SELECT s.content AS text, s.embedding AS vector
FROM project_<project_id>_result_sections s
WHERE s.content IS NOT NULL AND s.embedding IS NOT NULL
col_text: text
col_vector: vector
embedding: true
comparator: "<->"
limit: 10
model: gpt-4o-mini
promptTemplate: "À partir des sections, réponds à : {{query}}"
Barres de recherche
search_bar
Barre de recherche LLM avec modes configurables. Un panneau « documents liés » peut charger des lignes PostgreSQL via subboxOptions.related_documents. Rendu par app-chart-llmsearchbar.

Rendu du type search_bar.
Paramètres subboxOptions principaux :
Option |
Effet |
|---|---|
related_documents |
Configuration du panneau de documents liés. |
modes |
Modes de recherche disponibles. |
operator_search_bar
Barre de recherche avec opérateurs booléens (AND, OR, NOT). Rendu par app-chart-operator-searchbar.
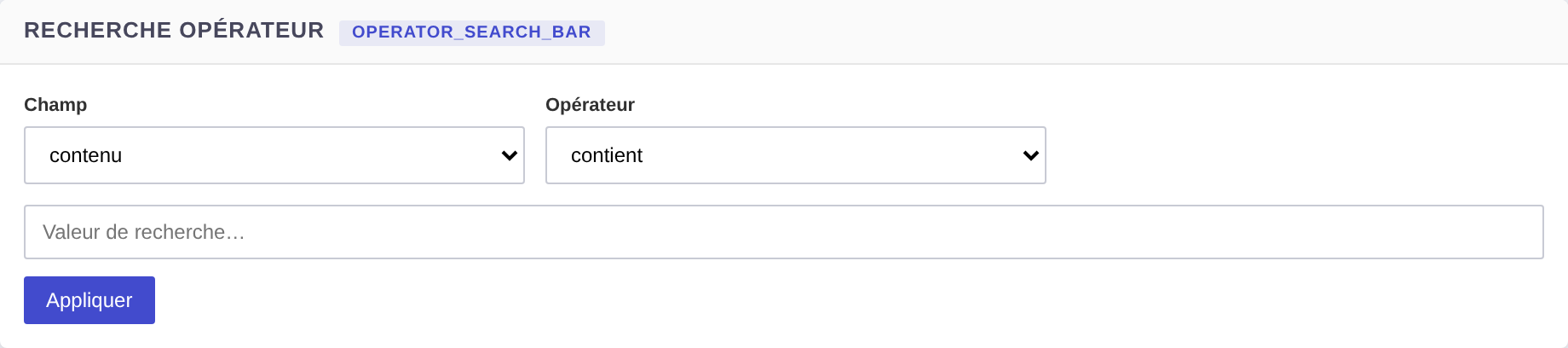
Rendu du type operator_search_bar.
llmdocuments
Recherche sémantique sur documents LLM (subbox et filtre homonyme). Affiche la barre de recherche documentaire.
Rendu du type llmdocuments.
Paramètres subboxOptions principaux :
Option |
Effet |
|---|---|
embedding |
Active la recherche par similarité. |
col_text / col_vector |
Colonnes source. |
text_engine
Moteur de texte / recherche avancée. Voir la fiche de diagnostic « zéro résultat » pour le dépannage des recherches infructueuses.
Rendu du type text_engine.
Voir aussi
Configuration des embeddings